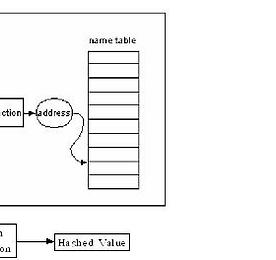
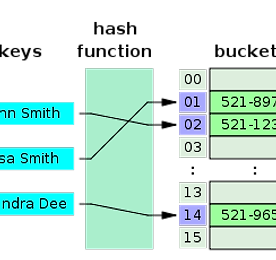
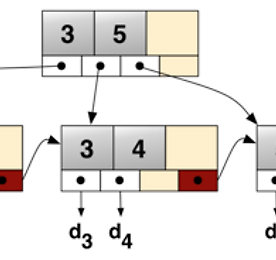
C.E/File processing 썸네일형 리스트형 DBMS에서 사용하는 B+ Tree B- tree vs B+ tree 1.모든 leaf의 depth 가 같다. 2.각 node에는 k/2 ~ k 개의 item이 들어있어야 한다. 3. search가 비슷하다. 4. add시 overflow가 발생하면 split 한다. 5. delete 시 underflow가 발생하면 redistribution 하거나 merge 한다. 1. B- tree의 각 node에는 key뿐 아니라 data 도 들어갈 수 있다. 여기서 data 는 disk block으로의 포인터가 될 수도 있다. B+ tree의 각 node에는 key 만 들어가야 한다. 그러므로 B+ tree에서 data는 오직 leaf 에만 존재한다. 2. B+ tree는 B- tree와는 달리 add,delete 가 leaf 에서만 이루어진다.(.. 더보기 extendible hashing(extendible hash/연장 해쉬/확장 해쉬) 정확히는 해싱(해슁)에 관한 글이지만 연장/확장 해쉬에 관한 개념을 잡기 위하여. I. 해슁의 개요 가. 해슁의 정의 - 여러개의 명칭(identifier)들이 무작위로 들어있는 테이블에서 특정 명칭을 찾고자 하는 경우 - Hashing 은 키 값에서 레코드가 저장되어 있는 주소를 직접 계산한 후 산출된 주소로 곧바로 접근이 가능하게 하는 방법. - 검색할 때 키 값을 비교하는 것이 아니라 계수적 성질을 이용, 계산에 의하여 주소를 결정하여 기억 공간에 레코드를 보관하거나 검색하는 방법 나. 해슁의 주요 개념 - 해쉬 함수(hash function) : 원하는 키값을 가지는 테이블 항목을 검색하기 위해 특정한 변환 함수 를 이용하여 키값을 항목 의 주소로 직접 바꿔서 검색하는 방법을 해슁이라 한다. 이때.. 더보기 해쉬 테이블 (해시 테이블/hash table) 완전정복+(Java) 해쉬 테이블(hash table) 해쉬 테이블은 키(key)라는 특별한 인덱스로 자료에 접근하는 배열로 구성되는 자료구조 이다. 해쉬 테이블의 해쉬 함수는 키 값을 받아 그 키의 해쉬값(hash coding 또는 hash value)을 리턴한다. 간단한 해쉬테이블을 시각적으로 표시했을 때, 아래와 같은 그림으로 표시할 수 있다. (Author: Jorge Stolfi, 원본: http://en.wikipedia.org/wiki/File:Hash_table_3_1_1_0_1_0_0_SP.svg) 해쉬 테이블의 장점은 상수 시간에 탐색이 가능한 것이다. 대신 다른 특징(혹은 단점?)은 순차적인 접근을 지원하지 않는 것이다. 따라서 이러한 특징에 맞는 상황에서 사용되어야 할 것이다. 추가적으로 해쉬 테이블의 .. 더보기 B+ 트리 개념 모든 레코드들이 트리의 최하위 레벨에 정렬되어 있고 트리 내부 블록에는 키들만 저장됨. 파일시스템 같은 블록기반 스토리지에서 저장데이터의 효율적인 검색에 유용함. 알고리즘 검색 Function: search (k) return tree_search (k, root); Function: tree_search (k, node) if node is a leaf then return node; switch k do case k < k_0 return tree_search(k, p_0); case k_i ≤ k < k_{i+1} return tree_search(k, p_i); case k_d ≤ k return tree_search(k, p_d); 삽입 1. 새 레코드를 삽입하기위한 검색을 수행 2. 노드.. 더보기 B트리 특징 및 개념 정렬된 데이터 보존. 로그시간내에 검색, 순차접근, 삽입, 삭제가 가능. 노드가 가득차 있지 않기 때문에 일정부분의 공간이 낭비됨. 모든 리프노드가 같은 깊이를 가지게 됨. B트리의 노드들은 여러개의 키를 가지고 있고, 이 키를 기준으로 하위트리들을 나누게 됨. 자식노드의 개수는 키개수+1 이 됨. 정의 각 노드의 키값은 하위트리들을 나누는 값이 되어야 함. 차수가 m인 B 트리는 다음 속성들을 만족시켜야 함. 1. 모든 노드는 최대 m 개의 자식들을 가져야한다. 2. 리프노드가 아닌 모든 노드(루트노드 제외)는 최소한 m/2개의 자식을 가져야 한다. 3. 루트 노드는 최소한 2개의 자식을 가져야 한다. 4. k개의 자식을 가지고 있는 리프노드가 아닌 노드는 k-1개의 키를 가진다. 5. .. 더보기 C++ 합병정렬 소스(merge sort in have data) /* CCL- 2014.05.20 http://breath91.tistory.com by_jacob(apodis91@naver.com/apodis91@ks.ac.kr) */ #include #include #include #define Max_Size 10 // 배열 사이즈 정의 //#define Rand_Num() rand() % 10 // 난수발생 전처리 void merge(int low, int mid, int high); void mergeSort(int low, int high); void printArr(int a[], int n); void copyArray(int start, int end); //시간함수관련 time_t t1, t2; // 빈 배열 static int mergeArr1[M.. 더보기 C++ 퀵정렬 소스(quick sort in have data) /* CCL- 2014.05.20 http://breath91.tistory.com by_jacob(apodis91@naver.com/apodis91@ks.ac.kr) */ #include #include #include /* 텍스트파일(.txt)의 이름과 Max_Size를 변경해주어야 합니다. */ #define Max_Size 150000 // 배열 사이즈 정의 #define SWAP( x, y, t ) ((t) = (x), (x) = (y), (y) = (t)) // 숫자 교환 전처리 //시간함수관련 time_t t1, t2; void Quick_sort( int*, int, int ); // 정렬 함수 int Partition ( int*, int, int ); // 분할 함수 int main( .. 더보기 C++ 정렬에 쓸 데이터 생성 #include #define Max_Size 200000 void main() { int i; FILE *fp = NULL; fp = fopen("data200000.txt", "w"); for(i=Max_Size;i>=0;i--) { fprintf(fp,"%d\n",i); } fclose(fp); } 더보기 이전 1 2 다음